
How to import an Excel file in RStudio?

Introduction
As we have seen in this article on how to install R and RStudio, R is useful for many kind of computational tasks and statistical analyses. However, it would not be so powerful and useful without the possibility to import datasets into R. As you will most likely use R with your own data, being able to import it into R is crucial for any user.
In this article I present two different ways to import an Excel file; (i) via the text editor and (ii) in a more “user-friendly” way. I also discuss about the main advantages and disadvantages of both methods. Note that:
- How to import a dataset often depends on the format of the file (Excel, CSV, text, SPSS, Stata, etc.). I focus here only on Excel files as it is the most common type of file for a dataset
- There are several other ways to import an Excel file (probably even some I am not aware of), but I present the two most simple yet robust ways to import such files
- No matter what type of file and how you import it, there is one gold standard regarding how datasets are structured: columns correspond to variables, rows correspond to observations (in the broad sense of the term) and each value must have its own cell (known as tidy format):
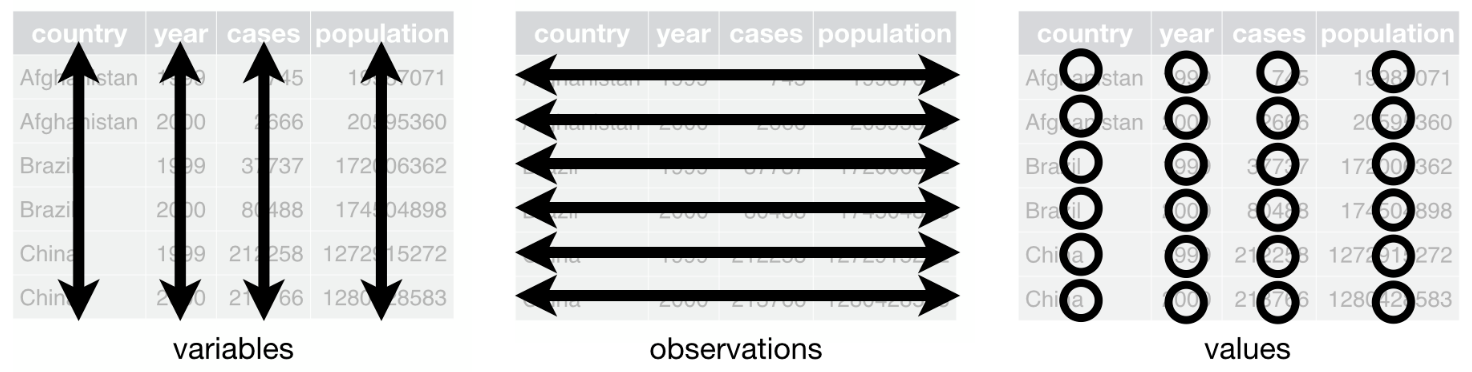
Structure of a dataset. Source: R for Data Science by Hadley Wickham & Garrett Grolemund
Transform an Excel file to a CSV file
Before dealing with the importation, the first thing is to change the format of your Excel file to a CSV format.1 CSV format is the standard when working with datasets and programming languages as it is a more robust format compared to Excel.
If your file is already in the CSV format (with the extension .csv), you can skip this section. If the file is not in the CSV format (for example the extension is .xlsx) you can easily transform it to CSV by following these steps:
- Open your Excel file
- Click on File > Save as
- Choose the format .csv
- Click on Save
Check that your file finishes with the extension .csv. If that is the case, your file is now ready to be imported. But first, let me introduce an important concept when importing datasets into RStudio, the working directory.
R working directory
Although programming languages may be very powerful, it often needs our help and importing a dataset is not an exception. Indeed, before importing your data, you must tell RStudio where your file is located (so let RStudio know in which folder to look for your dataset). But before this, let me introduce the working directory. The working directory is the location (in your computer) of where RStudio is currently working (in fact RStudio is not working across your entire computer; it is working inside one folder of your computer). Concerning this working directory, there are two functions that we will need:
getwd()(wdstands for working directory)setwd()
Get working directory
In most cases, when you open RStudio, the working directory (so where it is currently working) is different than where your dataset is located. To know what is the working directory RStudio is currently using, run getwd(). On MacOS, this function will most likely render a location such as "/Users/yourname/", while on Windows it will most likely render "c:/Documents/". Do not worry if your working directory is different, the most important is to set the working directory correctly (so where your file is located) and not where it is now.
Set working directory
As mentioned earlier, your dataset is most likely located in a different location than your working directory. Without any action from you, RStudio will never be able to import your file as it is not looking in the correct folder (you will encounter the following error in the console: cannot open file ‘data.csv’: No such file or directory). Now, in order to specify the correct location of your file (that is, to tell RStudio in which folder it should look for your dataset), you have three options:
- the user-friendly method
- via the console
- via the text editor (see below why it is my preferred option)
User-friendly method
To set the correct folder, so to set the working directory equal to the folder where your file is located, follow these steps:
- In the lower right pane of RStudio, click on the tab “Files”
- Click on “Home” next to the house icon
- Go to the folder where your dataset is located
- Click on “More”
- Click on “Set As Working Directory”
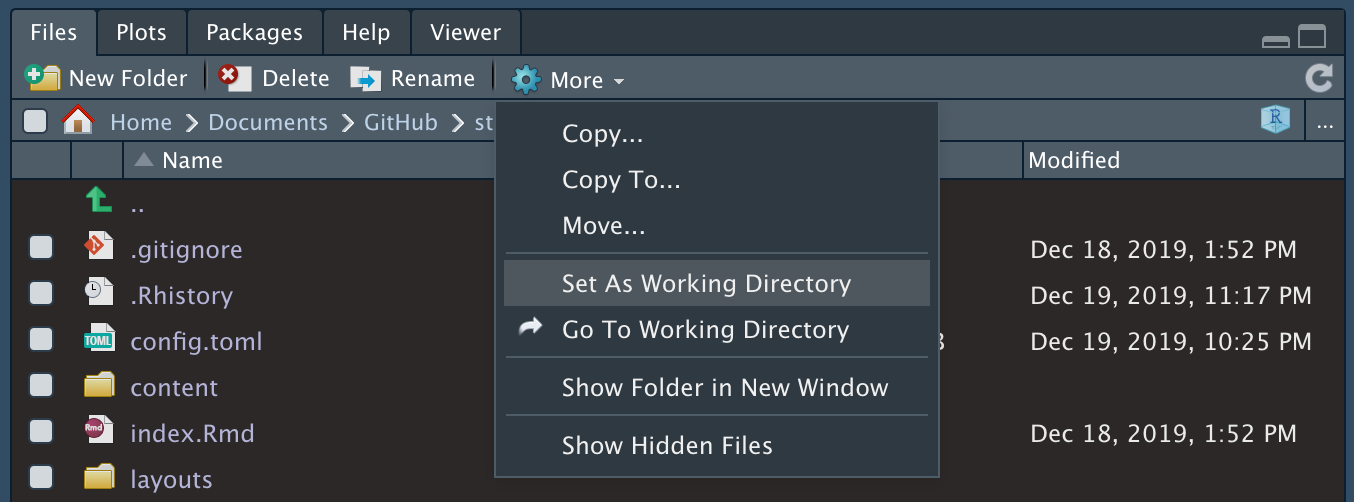
Set working directory in RStudio (user-friendly method)
Alternatively, you can also set the working directory by clicking on Session > Set Working Directory > Choose Directory…
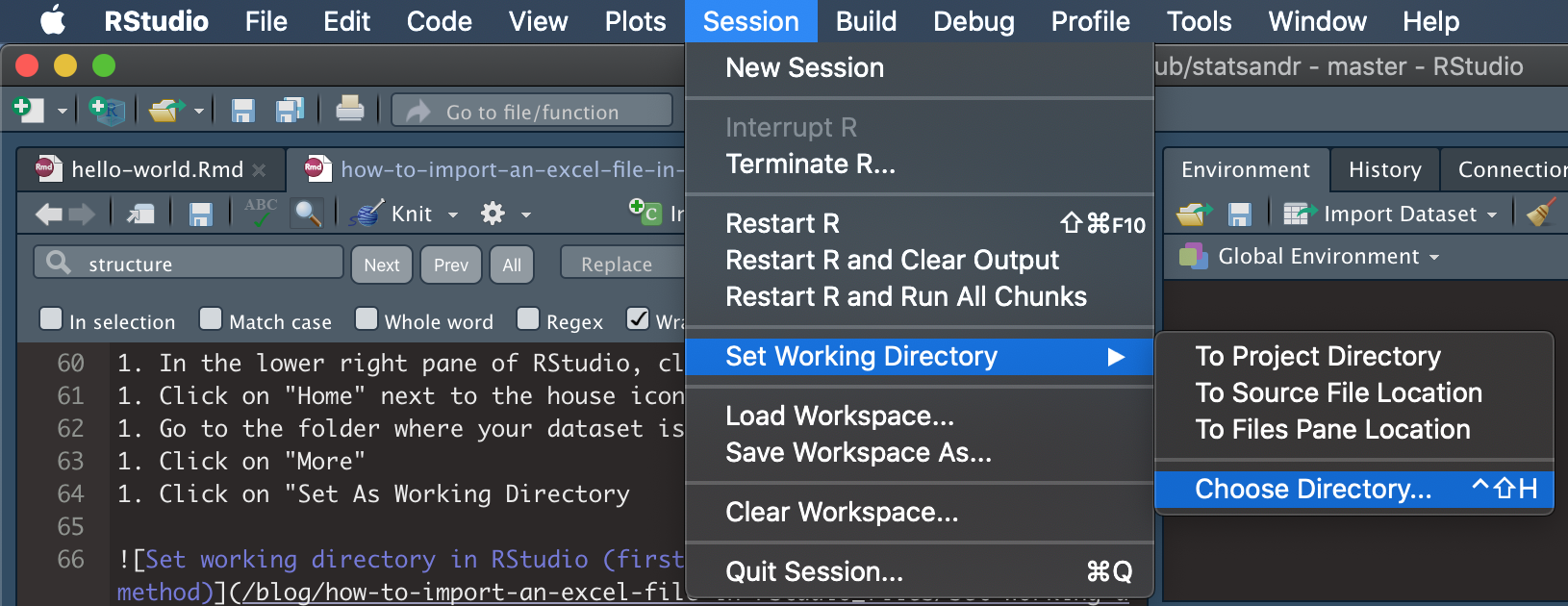
Set working directory in RStudio (user-friendly method)
As you can see in the console, any of the two methods will actually execute the code setwd() with the path to the folder you specified. So by clicking on the buttons you actually asked RStudio to write a line of code for you. This method has the advantage that you do not need to remember the code and that you will not make a mistake in the name of the path to your folder. The disadvantage is that if you leave RStudio and open it again later, you will have to specify the working directory again as RStudio did not save your actions via the buttons.
Via the console
You can specify the working directory by running setwd(path/to/folder) directly in the console, with path/to/folder being the path to the folder containing your dataset. However, you will need to run the command again when reopening RStudio.
Via the text editor
This method is actually a combination of the two above:
- Set the working directory by following the exact same steps than for the user-friendly method (via the buttons)
- Copy the code executed in the console and paste it in the text editor (i.e., your script)
I recommend this method for several reasons. First, you do not need to remember the setwd() function. Second, you will not make typos in the path of your folder (path which can sometimes be quite long if you have folders inside folders). Third, when saving your script (which I assume you do otherwise you would lose all your work), you also save the actions you just made via the buttons. So when you reopen your script in the future, no matter what is the current directory, by executing your script (which now include the line of code for setting the working directory), you will at the same time specify the working directory you selected for this project.
Import your dataset
Now that you have transformed your Excel file into a CSV file and you have specified the folder containing your data by setting the working directory, you are now ready to actually import your dataset. Remind that there are a two methods to import a file:
- in a user-friendly way
- via the text editor (see also below why it is my preferred option)
No matter which method you choose, it is a good practice to first open your file in TextEdit (on Mac) or Notepad (on Windows) in order to see the raw data. If you open the file in Excel you will see the data already formatted and thus miss some important information needed for the importation. Below an example of raw data:
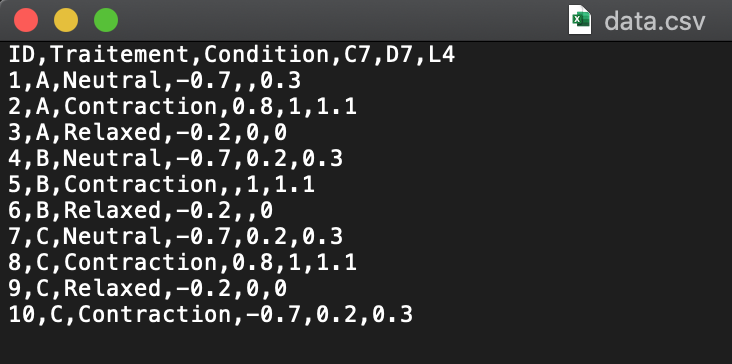
Example of raw data
There are a few things we need to look for in order to properly import our dataset:
- Are the variables names present?
- How are the values separated? Comma, semicolon, whitespace, tab?
- Is the decimal a point or a comma?
- How are specified missing values? Empty cells, NA, null, O, other?
User-friendly way
As shown below, simply click on the file > Import Dataset…
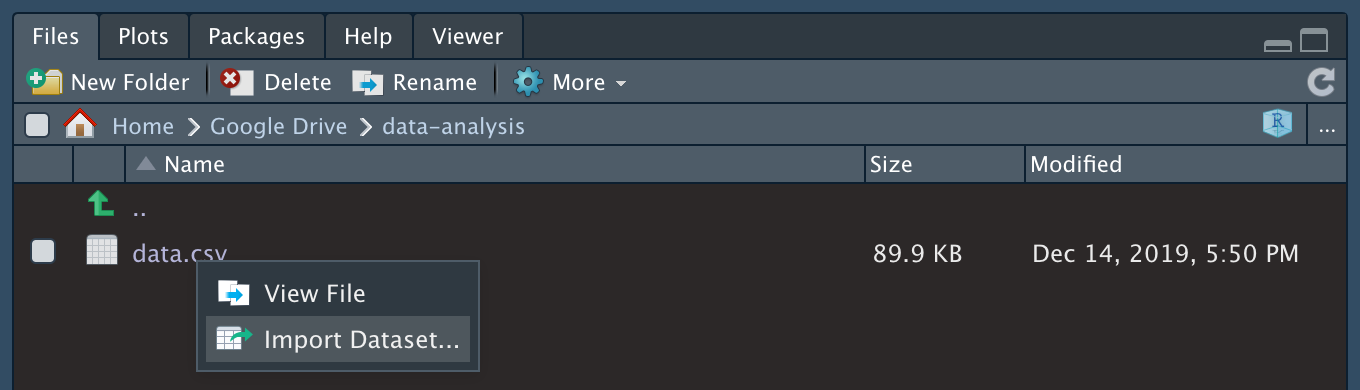
Import dataset in RStudio
A window which looks like this will open:
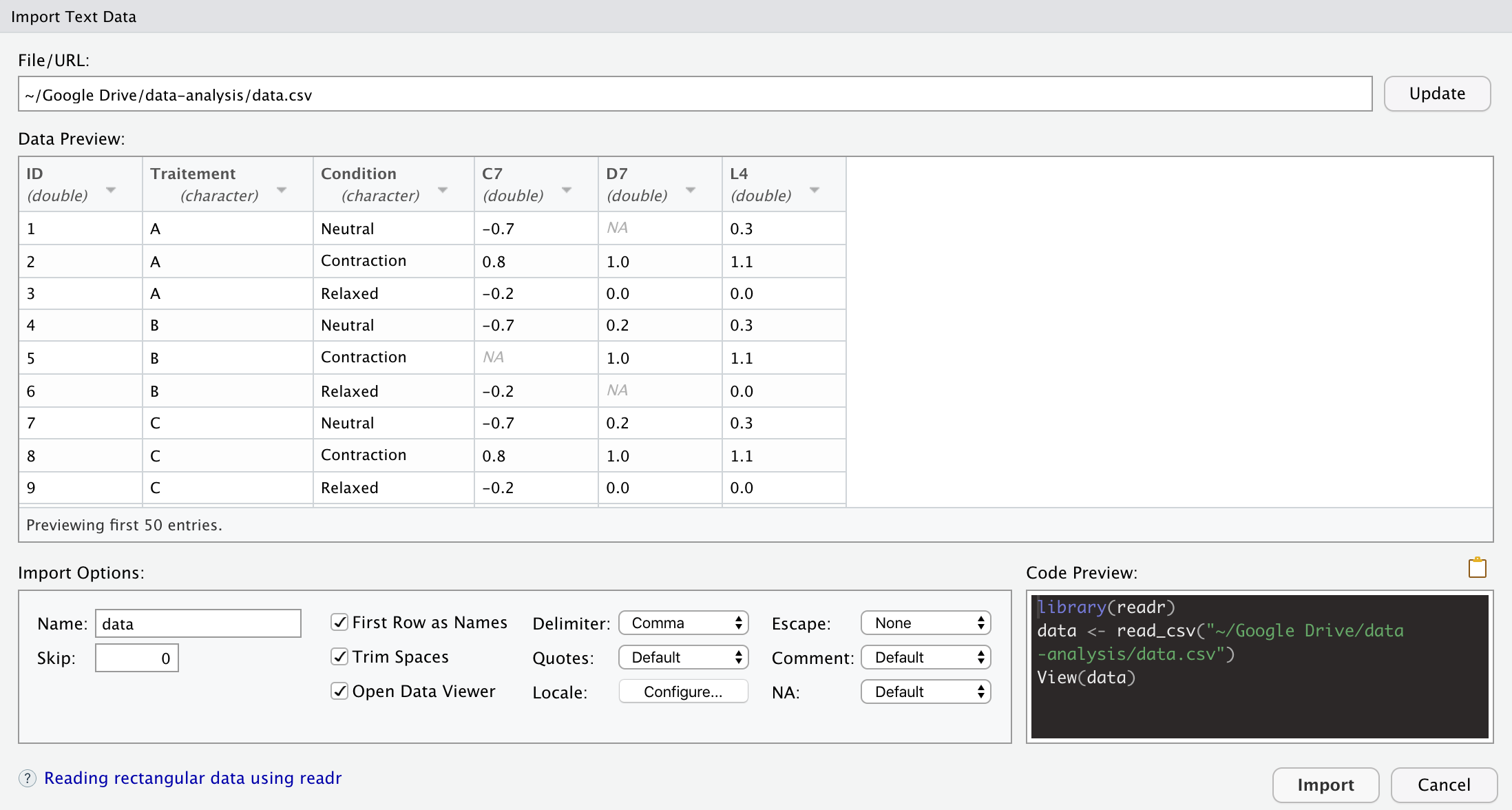
Import window in RStudio
From this window, you can have a preview of your data, and more importantly, check whether your data seems to have been imported correctly. If your data have been correctly imported, you can click on “Import”. If this is not the case, you can change the import options at the bottom of the window (below the data preview) corresponding to the information you gathered when looking at the raw data. Below, the import options you will most likely use:
- Name: set the name of your data set (default is the name of the file). Avoid special characters and long names (as you will have to type the name of your dataset several times). I personally rename my datasets with a generic name such as “dat”, others use “df” (for dataframe), “data”, or even “my_data”. You could use more explicit names such as “tennis_data” if you are using data on tennis matches for example. However, the main drawback with using specific names for datasets is that if, for instance, you want to reuse the code you created while analysing tennis data on other datasets, you will need to edit your code by replacing all occurrences of “tennis_data” by the name of your new dataset
- Skip: specify the number of top rows you want to skip (default is 0). Most of the time, 0 is fine. However, if your file contains some blank rows at the top (or information you want to disregard), set the number of rows to skip
- First Row as Names: specify whether the variables names are present or not (default is that variables names are present)
- Delimiter: the character which separate the values. From our raw data above, you can see that the delimiter is a comma (“,”). Change it to semicolon if your values are separated by “;”
- NA: how missing values are specified (default is empty cells). From our raw data above, you can see that missing values are simply empty cells, so leave NA to default or change it to “empty”. Change this option if missing values in your raw data are coded as “NA” or “0” (tip: do not code yourself missing values as “0”, otherwise you will not be able to distinguish the true zero values and the missing values)
After changing the import options corresponding to your data, click on “Import”. You should now see your dataset in a new window and from there you can start analyzing your data.
This user-friendly method has the advantage that you do not need to remember the code (see the next section for the entire code). However, the main drawback is that your import options will not be saved for a future usage so you will need to import your dataset manually each time you open RStudio.
Via the text editor
Similarly to setting the working directory, I also recommend using the text editor instead of the user-friendly method for the simple reason that you can save your import options when using the text editor (and not when using the user-friendly method). Saving your import options in your script (thanks to a line of code) allows you to quickly import your dataset the exact same way without having to repeat all the necessary steps every time you import your dataset. The command to import a CSV file is read.csv() (or read.csv2() which is equivalent but with other default import options). Here is an example with the same file than in the user-friendly method:
dat <- read.csv(
file = "data.csv",
header = TRUE,
sep = ",",
dec = ".",
stringsAsFactors = TRUE
)dat <-: name of the dataset in RStudio. This means that after importation, I will need to refer to the dataset by callingdatfile =: name of the file in the working directory. Do not forget “” around the name, the extension .csv at the end and the fact that RStudio is case sensitive ("Data.csv"will give an error) and space sensitive inside “” ("data .csv"will also throw an error). In our case the file is named “data.csv” sofile = "data.csv"header =: are variables names present? The default isTRUE, change it toFALSEif it is not the case in your dataset (TRUEandFALSEare always in capital letters,truewill not work!)sep =: separator. Equivalent to delimiter in the user-friendly method. Do not forget the ““. In our dataset the separator of the values is a comma sosep = ","dec =: decimal. Do not forget the ““. In our dataset, the decimal for the numeric values is a point, sodec = "."stringsAsFactors =: should character vectors be converted to factors? The default option used to beTRUE, but since R version 4.0.0 it isFALSEby default. If all your character vectors are actually qualitative variables (so factors in R), set it toTRUE- I do not write that missing values are coded as empty cells in my dataset because it is the default
- Last but not least, do not forget that the arguments are separated by a comma
Other arguments exist, run ?read.csv to see all of them.
After the importation you can check whether your data have been correctly imported by running View(dat) where dat is the name you chose for your data. A window, similar than for the user-friendly method, will display your data. Alternatively you can also run head(dat) to see the first 6 rows and check that it corresponds to your Excel file. If something is not correct, edit the import options and check again. If your dataset has been correctly imported, you can now start analyzing your data. See other articles on R if you want to learn how.
The advantage of importing your dataset directly via the code in the text editor is that your import options will be saved for a future usage, preventing you from importing it manually every time you open your script. You will, however, need to remember the function read.csv() (not the arguments since you can always check them in the help documentation).
Import SPSS (.sav) files
Only Excel files are covered in details here. However, SPSS files (.sav) can also be read in R by using the following command:
library(foreign)
dat <- read.spss(
file = "filename.sav",
use.value.labels = TRUE,
to.data.frame = TRUE
)The read.spss() function outputs a data table which retrieves all the characteristics of the .sav file, including the names given for the different levels of the categorical variables and the characteristics of the variables. If you need more information about this command, see the help documentation (library(foreign) then ?read.spss).
Conclusion
Thanks for reading.
I hope this article helped you to import an Excel file in RStudio. Now that your dataset is correctly imported, learn how to manipule it or how to perform descriptive statistics in R.
As always, if you have a question or a suggestion related to the topic covered in this article, please add it as a comment so other readers can benefit from the discussion.
I am aware that it is possible to import an Excel directly into R without converting it in a CSV file, with the
read_excel()function from the{readxl}package for instance. However, CSV format is the standard and more importantly, importing a CSV does not require to install and load a package (which is sometimes confusing for beginners).↩︎
Liked this post?
- Get updates every time a new article is published (no spam and unsubscribe anytime)
- Support the blog
- Share on:



